深度学习笔记——归一化、正则化

大家好,这里是Goodnote(好评笔记)。本笔记介绍深度学习中常见的归一化、正则化。

各种优化的归一化介绍(本质上进行标准化)
归一化是对输入数据或网络中间层的输出进行标准化处理,使其分布更加稳定,从而加速训练并提高模型性能。
下面的归一化。本质上进行的是标准化。
普通归一化(例如 BN、LN等)通常放在全连接层或卷积层之后,并在激活函数之前。
权重归一化与普通的归一化不同,它是直接应用于层的权重参数,因此它通常在层的定义阶段就应用。例如,在卷积层或全连接层的权重初始化或定义时。
普通归一化过程
归一化方法的统一步骤如下:
1. 确定归一化范围
- 批归一化(Batch Normalization)
- 层归一化(Layer Normalization)
- 实例归一化(Instance Normalization)
- 组归一化(Group Normalization)
2. 计算均值和方差
- 对归一化范围内的元素计算均值 和方差 。
- 公式如下:
- 其中 是归一化范围内的元素总数。
3. 标准化
- 将输入值进行标准化,使其具有均值 0 和方差 1:
- 是一个小常数,用于避免分母为零。
4. 缩放和平移
- 为了让模型在归一化后仍能保持灵活性,引入可学习的缩放参数 和平移参数 :
- 通过学习 和 ,模型可以调整归一化后的输出尺度和偏移,使其更加适应模型的需求。
普通归一化分类
1. 批归一化(Batch Normalization, BN)
原理
对一个批量中的样本的同一通道进行归一化。它将每个神经元的输出值转换为均值为0、方差为1的分布,随后再进行缩放和平移。批归一化的公式如:
其中 和 是当前批次中的均值和方差, 是一个小常数,防止除零错误。
优点
- 减少了内部协变量偏移问题,使得模型更稳定。
- 加速收敛,允许使用更高的学习率。
- 有轻微的正则化效果,因为批次间的随机性类似于dropout的效果。
缺点
- 对小批量数据敏感。当批次较小时,均值和方差估计不准,导致效果下降。
- 在某些情况下(如RNN、Transformer中的序列任务),批次归一化的效果不如其他归一化方法。
- 训练和推理时行为不同:推理时使用全局的均值和方差,因此需要额外的记录和计算。
使用场景
- 适用于大多数卷积神经网络(CNN)和全连接网络(MLP),如图像分类、物体检测等任务中。
- 不太适合处理序列任务,如RNN和LSTM。
2. 层归一化(Layer Normalization, LN)
原理
对单个样本的所有通道进行归一化,不依赖批量。
- 公式类似于批归一化,但均值和方差是基于整个层(而不是批次)计算的。
- 其中和是当前层中的均值和方差。
优点
- 对小批次数据敏感性较低,不依赖于批次大小。
- 在处理序列数据(如RNN、Transformer)时效果更好,因为它不依赖于批次中的样本数。
缺点
- 相比批归一化,计算量稍大。
- 由于没有利用批次之间的信息,收敛速度可能稍慢。
使用场景
- 适用于序列任务,如RNN、LSTM、Transformer模型等,尤其在自然语言处理和时间序列任务中广泛使用。
3. 实例归一化(Instance Normalization, IN)
原理
对单张图像的每个通道分别独立进行归一化,不依赖批量。
- 公式类似于批归一化,但归一化的维度是单个样本的每个通道:
优点
- 适合风格迁移、图像生成等任务,因为在这些任务中,局部统计量(如样本和通道内的均值和方差)比批次统计量更重要。
- 对风格变化的敏感度更高。
缺点
- 不适合大多数分类任务,因为它只考虑样本的单个通道,不利用全局信息。
使用场景
- 广泛用于图像生成任务中,如GAN和风格迁移(Style Transfer)等。
- 在卷积神经网络中常见于图像处理任务。
4. 组归一化(Group Normalization, GN)
原理
组归一化是介于实例归一化和层归一化之间的一种方法。它将单个样本的特征通道分为若干组,并在每组内进行归一化操作。这种方法避免了批归一化对批次大小的依赖,同时利用了更多的局部信息。
- 公式与批归一化类似,但均值和方差是在每组特征通道内计算的:
- 其中 和 是当前组内的均值和方差。
优点
- 对小批次训练效果良好,不依赖于批次大小。
- 比层归一化更有效,特别是在卷积神经网络中,能很好地利用局部特征。
缺点
- 对卷积核的大小和特征通道数敏感,不如批归一化适用于大批次训练任务。
使用场景
- 适用于卷积神经网络(CNN)中的图像分类任务,特别是小批次训练场景。
- 当批归一化效果不佳或批次较小时(如语义分割、目标检测等任务)表现优越。
权重归一化(Weight Normalization, WN)
原理
权重归一化是对神经网络中的权重进行归一化,而不是激活值(准备通过激活函数(如 ReLU、Sigmoid、Tanh 等)的值)。它通过对每个神经元的权重向量进行重新参数化,将权重向量的方向与其长度分离开。
权重归一化主要针对模型的权重参数,确保训练中权重更新稳定。
批/层/实例/组归一化主要针对层的激活值,确保每层输出的稳定分布,从而提高训练的速度和稳定性。
权重归一化的步骤
权重归一化的过程可以分为以下几个步骤:
1.重参数化权重:
- 将每个权重向量重参数化为方向向量和长度标量的乘积。
- 具体表示为:
- 其中:
- 是原始权重向量(可学习参数),
- 是权重向量的范数(即它的长度),
- 是可学习的标量(称为“尺度参数”),
- 是归一化后的权重向量。
- 通过这种重参数化,权重向量 的方向被标准化为单位长度(归一化),而 g 控制权重的尺度。
2.计算范数:
- 计算权重向量的 L2 范数:
- 该范数用于对权重向量进行标准化,使得其长度等于 1。
3.标准化权重:
- 使用计算出的范数将权重向量标准化,得到单位长度的方向向量:
- 这个标准化的方向向量 仅包含方向信息,而没有尺度信息。
4.应用缩放:
- 使用可学习的尺度参数 g 来调整权重的实际尺度,使得网络能够灵活调整权重的大小:
- 通过引入这个缩放参数 g ,模型可以学习适当的权重大小,以适应不同的训练和优化需求。
5.权重更新:
- 在反向传播时,优化器会更新原始权重 和缩放参数 g 的值,而不是直接更新标准化后的权重 。这种重参数化不会改变优化问题,但可以提高训练的稳定性。
权重归一化的作用
- 提高收敛速度:权重归一化通过标准化权重的长度,使得不同层的权重尺度在训练中保持一致,减轻了梯度爆炸或消失的问题,从而加速训练收敛。
- 更稳定的训练过程:权重归一化减少了权重值的剧烈变化,使优化过程更加平滑和稳定。
- 增强模型的可解释性:通过将权重分解为方向和尺度两个部分,模型的行为更容易解释,因为方向向量决定了特征的方向,而缩放参数决定了特征的重要性。
优点
- 可以加速收敛,并提高模型的稳定性。
- 在一定程度上减少了对批次大小的依赖。
缺点
- 相较于批归一化,效果并不总是显著。
使用场景
- 适用于卷积神经网络和全连接网络,尤其在需要加速训练时。
- 在一些生成模型中(如GAN)也有应用。
归一化方法对比总结
以下是归一化方法对比总结,其中加入了每种归一化方法的原理:
| 归一化方法 | 原理 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 批归一化(BN) | 对一个批量中的所有样本的同一通道进行归一化,基于批次的均值和方差调整 | 卷积网络、全连接网络 | 加快收敛,正则化,适应大批量训练 | 对小批次敏感,序列任务效果差 |
| 层归一化(LN) | 对单个样本的所有通道进行归一化,不依赖批量,计算层内均值和方差 | RNN、Transformer、序列任务 | 适应小批次训练,不依赖批次大小 | 计算量较大,收敛可能稍慢 |
| 实例归一化(IN) | 对单张图像的每个通道分别独立进行归一化,计算每个样本的通道内均值和方差 | 图像生成、风格迁移 | 对风格敏感,适用于生成任务 | 不适合分类任务,无法捕捉全局信息 |
| 组归一化(GN) | 将单个样本的特征通道分组,对每一组进行归一化,计算组内均值和方差 | 小批次训练,卷积网络 | 适合小批次,不依赖批次大小 | 对卷积核大小和通道数较敏感 |
| 权重归一化(WN) | 对神经元的权重向量进行归一化,将方向和长度分开重新参数化 | 卷积网络、全连接网络、生成模型 | 加速收敛,提高稳定性 | 效果不一定显著,某些任务中不如BN |
注意,虽然他们是叫做归一化(批归一化、层归一化、实例归一化),是将多个输入特征归一化为均值为 0、方差为 1 的分布,使得网络的各层输入保持在较为稳定的范围内。本质上是进行标准化。再进行引入两个可学习参数 γ 和 𝛽,分别表示缩放和平移操作。
BN、LN、IN、GN 等归一化方法都包含了标准化的步骤,即它们都会将激活值调整为均值为 0、方差为 1 的分布,关键区别在于这些方法在不同的范围内计算均值和方差,以适应不同的训练场景和模型结构:
Transformer模型选择Layer Normalization而不是Batch Normalization的主要原因在于以下几点:
- 处理变长序列: Batch Normalization要求固定大小的batch,从而成功计算均值和方差。这在变长序列中难以实现。而Layer
Normalization则是对每一个实例进行归一化,适用于变长序列的输入。- 训练稳定性: Batch Normalization在RNN和Transformer这样的序列模型中可能会导致训练过程不稳定,因为它依赖于整个batch的数据进行归一化,而序列之间有时会有较大的差异。
- 在线推断: 在推断阶段,Transformer有时会逐步生成序列,在这种情况下,无法利用整个batch的信息。Layer Normalization在这种单一实例情况下表现更好。
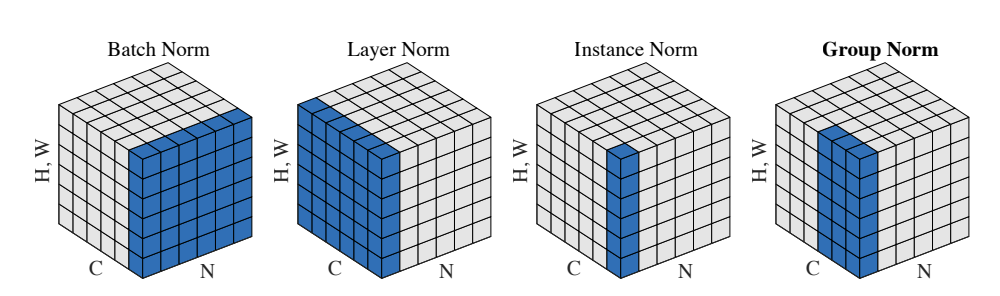
- Batch Normalization (BN):对一个批量中的所有样本的同一通道进行归一化。
- Layer Normalization (LN):对单个样本的所有通道进行归一化,不依赖批量。
- Instance Normalization (IN):对单张图像的每个通道分别独立进行归一化,不依赖批量。
- Group Normalization (GN):对单张图像的多个通道进行归一化,不依赖批量。
正则化
正则化是通过在损失函数中加入额外的约束项,限制模型参数的大小,从而 防止过拟合,提高模型的泛化能力。
L1 正则化(Lasso)
原理
L1正则化通过在损失函数中加入权重的绝对值和来约束模型复杂度。其目标函数为:
其中,是正则化强度,是第个特征的权重。
使用场景
- 特征选择:L1 正则化能够将部分不重要的特征权重缩减为 0,从而实现特征选择。
- 高维稀疏数据集:如基因数据分析,模型能够自动去除无关特征。
优缺点
- 优点:生成稀疏解,易于解释,自动选择重要的特征。
- 缺点:对特征高度相关的数据,随机选择特征,模型不稳定。
L2 正则化(Ridge)
原理
L2正则化通过在损失函数中加入权重的平方和来约束模型复杂度。其目标函数为:
其中,是正则化强度,是第个特征的权重。
使用场景
- 多重共线性问题:在特征间存在多重共线性的情况下,L2 正则化能够减小模型方差,防止模型对数据的过拟合。
- 回归任务:如岭回归(Ridge Regression)中常用来提升模型鲁棒性。
优缺点
- 优点:防止模型过拟合,能有效处理特征多重共线性问题。
- 缺点:不能进行特征选择,所有特征权重都被减小。
Elastic Net 正则化
定义
Elastic Net 是 L1 和 L2 正则化的结合,它同时引入了 L1 和 L2 正则化项,在获得稀疏解的同时,保持一定的平滑性。
公式
其中,和控制L1和L2正则化的权重。
优点
- 结合了 L1 和 L2 正则化的优点,既能够稀疏化模型,又不会完全忽略相关性特征。
- 对高维数据和特征之间存在高度相关性的数据表现良好。
缺点
- 相比于单独使用 L1 或 L2 正则化,它有更多的超参数需要调节。
应用场景
- 常用于具有高维特征的数据集,特别是在需要稀疏化的同时,又不希望完全丢失特征之间相关性的信息。
Dropout
原理
Dropout 是一种用于深度神经网络的正则化方法。训练过程中,Dropout 随机将部分神经元的输出设置为 0,防止神经元对特定特征的依赖,从而提升模型的泛化能力。类似集成学习,每次生成的都不一样。丢弃概率 (p),通常设置为 0.2 到 0.5。
使用场景
- 深度神经网络:在深度学习中广泛应用,如卷积神经网络(CNN)、循环神经网络(RNN)等。
- 避免过拟合:尤其在模型复杂、训练数据较少的场景中,能够有效降低过拟合风险。
优缺点
- 优点:有效防止过拟合,提升模型鲁棒性。
- 缺点:训练时间较长,推理过程中不适用。
早停法(Early Stopping)
原理
早停法是一种防止模型过拟合的策略。在训练过程中,监控验证集的误差变化,当验证集误差不再降低时,提前停止训练,防止模型过拟合到训练数据。
使用场景
- 深度学习:几乎适用于所有深度学习模型,在神经网络训练中常用,防止训练过度拟合。
- 梯度下降优化:在任何基于梯度下降的优化过程中均可使用,如线性回归、逻辑回归等。
优缺点
- 优点:简单有效,能够动态调节训练过程。
- 缺点:需要合理设置停止条件,可能导致模型欠拟合。
Batch Normalization (BN)
虽然 Batch Normalization(BN)通常被认为是一种加速训练的技巧,但它也有正则化的效果。BN 通过对每一批次的输入进行归一化,使得模型训练更加稳定,防止过拟合。
原理
BN 通过将每个批次的激活值标准化为均值为 0,方差为 1,然后通过可学习的缩放和平移参数恢复特征分布。由于批次间的变化引入了一定的噪声,这对模型有一定的正则化作用。
使用场景
- 广泛应用于卷积神经网络(CNN)和全连接网络(FCN)中。
优点
- 提升训练速度,并有一定的正则化效果。
- 适合卷积神经网络和全连接神经网络,能有效减少过拟合。
缺点
- 在小批量训练时效果不稳定。
- 引入了额外的计算开销。
权重衰减(Weight Decay)
权重衰减是一种通过直接对权重进行衰减的正则化方法,它等价于 L2 正则化。
原理
在每次权重更新时,加入一个权重衰减项,使得权重参数逐渐减小,从而防止权重变得过大,减少模型的复杂度。
权重衰减直接在梯度更新中对权重施加一个额外的缩减项,而不需要在损失函数中添加正则化项。也就是说,权重衰减是通过直接操作梯度更新公式中的权重来实现的。
公式:
其中:
- 是学习率。
- 是权重衰减系数。
- 是模型的权重。
其中 λ 是正则化系数,控制惩罚项的强度。该惩罚项会在每次梯度更新时对权重施加一个减小的力度,从而限制权重的增长。
L2正则化和权重衰减目标一致、数学形式相似,但是并不是同一种手段:
实现方式:
- L2 正则化:在传统的 L2 正则化中,惩罚项是直接添加在损失函数中。因此,反向传播时会计算这个惩罚项的梯度,并将它加入到权重的更新中。优化器仅对
Loss求导。- 权重衰减:在权重衰减中,惩罚项不直接添加到损失函数中,而是在梯度更新时作为一个附加的“权重缩小”操作。在每次更新时,优化器会自动将权重按比例缩小。例如,对于SGD 优化器,权重更新公式变成:
- 这里,是直接对权重施加的缩小因子,而不影响梯度方向。
优化器依赖:
- L2 正则化:不依赖于特定的优化器。正则项直接通过损失函数梯度传播,适用于所有优化器。
- 权重衰减:有些优化器(如 AdamW)在实现时将权重衰减项独立处理,而不会将其纳入损失的反向传播中。
使用场景
- 与 SGD 等优化器配合使用效果较好,尤其适用于大型神经网络,可以防止权重过大导致的过拟合。对于 Adam 优化器,建议使用 AdamW 版本来获得更合适的权重衰减效果。
优点
- 类似于 L2 正则化,简单易用,有效减少过拟合。
缺点
- 与 L2 正则化非常相似,但在某些优化器(如 Adam)中,权重衰减的实现可能会与 L2 正则化略有不同。在这些情况下,直接使用 L2 正则化可能会更符合预期的效果。
剪枝(Pruning)
剪枝通常在模型训练完成后进行,作为一种后处理技术。例如决策树中的剪枝操作。
原理
剪枝通过删除神经网络中重要性较低的连接或神经元,减少模型规模,从而达到简化网络的目的。剪枝不仅可以减少计算量和存储需求,还能在一定程度上防止过拟合,使模型在推理时更加高效。
应用场景
- 移动和嵌入式设备:剪枝特别适用于资源受限的设备(如手机、嵌入式系统、物联网设备)上,以减小模型尺寸和降低推理时间。
- 深度学习模型加速:剪枝广泛用于加速深度神经网络的推理过程,特别是在需要实时处理的任务中,如自动驾驶、图像识别等。
- 大规模模型压缩:在大规模模型(如大规模卷积神经网络、语言模型)中,剪枝可以显著减少计算量,使得模型更高效地运行。
优点
- 减少模型复杂度:剪枝可以显著减少网络中的参数,降低计算和内存需求,使得模型更适合在资源有限的设备上(如移动设备、嵌入式系统)运行。
- 提高模型的泛化能力:通过移除不重要的权重和神经元,减少模型对特定数据特征的过拟合,从而提高泛化能力。
- 加速推理:剪枝后的模型由于参数减少,推理速度得到显著提升。
缺点
- 需要额外的剪枝步骤
- 可能影响模型性能:如果剪枝不当,可能会削弱模型的表现,模型的准确性可能会大幅下降。
- 需要重新训练:剪枝后的模型有时需要重新微调或训练,以恢复模型性能。
以下是关于常见正则化方法的总结表格:
| 正则化方法 | 原理 | 使用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| L1 正则化 (Lasso) | 通过增加权重绝对值惩罚项,实现特征稀疏化,部分权重缩减为 0。 | 高维稀疏数据集,特征选择任务。 | 生成稀疏解,易于解释,自动选择重要的特征。 | 对特征高度相关的数据,可能随机选择特征,导致模型不稳定。 |
| L2 正则化 (Ridge) | 通过增加权重平方和惩罚项,减小权重大小,防止权重过大。 | 多重共线性问题、回归任务,如岭回归。 | 防止模型过拟合,处理特征多重共线性问题,模型更加鲁棒。 | 无法进行特征选择,所有特征权重都被减小。 |
| Elastic Net 正则化 | L1 和 L2 正则化结合,既稀疏化模型,又保留相关性特征。 | 高维特征的数据集,稀疏化和相关性特征共存的场景。 | 结合 L1 和 L2 优点,稀疏化与平滑化并存,适用于高维数据。 | 增加了超参数调节的复杂性。 |
| Dropout | 训练时随机丢弃部分神经元输出,防止神经元对特定特征的依赖,提升泛化能力。 | 深度神经网络,CNN、RNN,适合复杂模型或数据较少的场景。 | 有效防止过拟合,提升模型鲁棒性。 | 训练时间较长,推理时不适用。 |
| 早停法 (Early Stopping) | 监控验证集误差,验证集误差不再下降时提前停止训练,防止过拟合。 | 深度学习模型,梯度下降优化任务,如线性回归、逻辑回归。 | 简单有效,动态调节训练过程,减少过拟合。 | 需要合理设置停止条件,可能导致欠拟合。 |
| Batch Normalization (BN) | 对每一批次的输入进行归一化,保持训练过程中的稳定性,并有一定正则化效果。 | 卷积神经网络和全连接神经网络,适用于大批量训练。 | 加速训练,减少过拟合,提升模型稳定性。 | 小批量训练时效果不稳定,增加计算开销。 |
| 权重衰减 (Weight Decay) | 在每次权重更新时加入权重衰减项,防止权重过大,等价于 L2 正则化。 | 大规模神经网络,常与 SGD、AdamW 等优化器配合使用。 | 简单有效,减少过拟合,类似 L2 正则化。 | 与 L2 略有不同,某些优化器中的效果不同。 |
| 剪枝 (Pruning) | 训练后移除神经网络中不重要的连接或神经元,减少模型规模,降低计算量,提升泛化能力。 | 移动设备、嵌入式系统、大规模模型压缩,适合资源受限设备和加速任务。 | 减少模型复杂度,提升推理速度,适合资源受限设备。 | 需要额外剪枝步骤,可能影响模型性能,需要重新训练。 |
这个表格总结了常见的正则化方法,涵盖了其工作原理、使用场景、优点和缺点。根据具体任务和数据集,可以选择合适的正则化方法来提高模型的泛化能力和训练效率。
Q&A
权重归一化和权重衰减的异同
二者都作用于模型的权重。都是用来提升泛化能力。但是有下面的不同:
| 特性 | 权重归一化 | 权重衰减 |
|---|---|---|
| 主要目的 | 提升训练稳定性,帮助模型更快收敛 | 正则化,防止过拟合 |
| 实现方式 | 将权重分解为范数和方向 | 损失函数中增加 L2 正则化项,将权重缩小 |
| 应用位置 | 在使用权重归一化的层(例如卷积层或全连接层)中 | 在优化器的更新(如 SGD、Adam)步骤中,通过正则化参数应用 |
| 对梯度的影响 | 不影响权重的梯度更新计算 | 对每次权重更新施加惩罚,直接减小权重值 |
| 是否显式操作 | 是,对权重重参数化 | 否,通过损失函数中添加正则项间接实现 |
- 权重归一化:用于训练时提高稳定性和收敛速度,对权重进行重参数化分解,直接应用在层的权重上。
- 权重衰减:用于防止过拟合,对损失函数中的权重平方项施加惩罚,通过优化器在每次权重更新时施加影响。