多模态论文笔记——CLIP

大家好,这里是Goodnote(好评笔记)。本文详细介绍这几年AIGC火爆的隐藏功臣,多模态模型:CLIP,通过对比学习进行图像-文本联合学习。

CLIP(Contrastive Language-Image Pre-training)
CLIP 是由 OpenAI 提出的一个用于多模态学习的模型,通过对比学习(contrastive learning)进行图像-文本联合学习的创新模型。CLIP 训练图像和文本的联合表示。
论文:Learning Transferable Visual Models From Natural Language Supervision
1. CLIP 的核心思想
CLIP 的核心思想是将图像和文本映射到一个共享的嵌入空间中,并通过对比学习来最大化匹配图像-文本对之间的相似度,最小化不匹配图像-文本对的相似度。模型通过大量数据上进行预训练,具备强大的通用化能力,即零样本学习(zero-shot learning),这意味着它可以处理没有见过的任务或类目而无需重新训练。
2. CLIP 的模型架构
CLIP 的架构包括图像编码器和文本编码器,它们分别将图像和文本输入嵌入到同一个向量空间。图像和文本分别经过编码后,计算它们在向量空间中的相似度来进行对比学习。
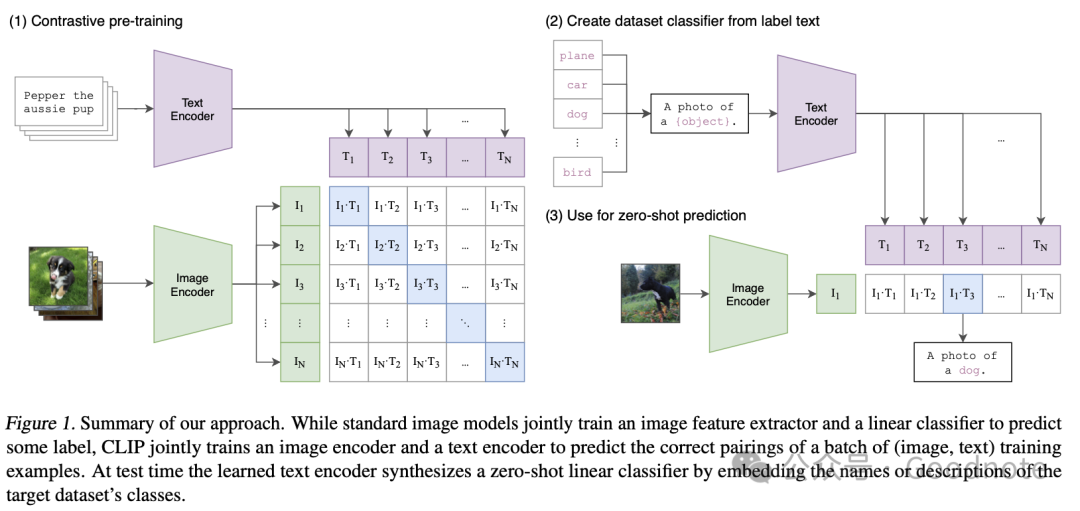
图 1. 我们方法的概述。标准图像模型会联合训练一个图像特征提取器和一个线性分类器来预测标签,而 CLIP 则联合训练一个图像编码器和一个文本编码器,以预测一批(图像、文本)训练示例的正确配对。在测试时,学习到的文本编码器通过嵌入目标数据集的类别名称或描述来合成一个零样本目标线性分类器。
2.1 图像编码器
CNN(如 ResNet)或 Vision Transformer (ViT) 作为图像编码器
- ResNet 或 ViT 接受图像作为输入,并输出包含了图像的高层语义信息的向量。
ViT详细介绍参考:多模态论文笔记——ViT、ViLT
2.2 文本编码器
Transformer 作为文本编码器。这个编码器会将输入的文本描述(自然语言)转化为一个向量表示。
- 文本编码器会将每个文本通过多层 Transformer 的处理,生成包含了文本的语义信息向量。
2.3 对比学习机制
CLIP 的训练目标:通过对比学习(contrastive learning) 的损失函数 让正确的图像-文本对的表示在向量空间中尽可能接近,而错误的图像-文本对在向量空间中尽可能远离。
2.4 对比损失(Contrastive Loss)
对比损失(Contrastive Loss):CLIP 使用了一种基于InfoNCE的对比损失函数。对于每一对图像-文本,模型会计算图像和所有文本对(以及文本和所有图像对)的相似度。通过最大化匹配对的相似度,同时最小化不匹配对的相似度,CLIP 可以学到更强的多模态表示。
InfoNCE
损失函数的目标是让图像 ;与正确文本描述 的相似度最大化,同时与所有其他不相关文本 的相似度最小化,公式为:
- :第个图像样本。
- :第个图像样本的正确文本描述。
- :其他文本描述(包括和其他与不匹配的文本描述)。
- :图像和文本或者的相似度,一般使用余弦相似度来计算。
- :温度参数,用于控制相似度分布的平滑程度。
可以使用余弦相似度:
其中 ( ) 是图像 ( ) 的嵌入向量,( ) 是文本 ( ) 的嵌入向量。这样计算得到一个 相似度矩阵,矩阵中的每个元素表示批次中任意一对图像和文本的相似度。
由于CLIP 包含两个主要的编码器部分:图像编码器、文本编码器,所以,损失函数需要分为两部分,针对之后图像编码器的损失函数 和 文本编码器的损失函数。之后根据各自的损失函数优化两部分构件的权重。
- 其实损失函数都是一样的,只不过因为CLIP组成构件是两部分,所以需要分两部分,方便优化各自的权重参数,当单独使用图像编码器或者文本编码器时候(SD模型单独使用Text Encoder),也会有很好的效果。
- 确保图像和文本的嵌入能够在共享的嵌入空间中彼此对齐(无论是从图像到文本,还是从文本到图像,匹配的对之间的相似度都被最大化,不匹配的对之间的相似度都被最小化。),从而在跨模态任务中实现一致性和相互匹配的能力。
图像编码器损失函数
作用于图像检索文本:给定一个图像,可以找到与之最匹配的文本描述。
图像损失部分:对于每一个图像 ( ),该部分的损失最大化它与正确文本 ( ) 的相似度,同时最小化它与其他错误文本 ( ) 的相似度。这一部分确保了图像能够找到正确的文本,也就是说图像编码器能够将图像嵌入到一个空间中,使得匹配的文本描述与它更接近。
文本编码器损失函数
作用于文本检索图像:给定一个文本描述,可以找到与之最匹配的图像。
- 文本损失部分:对于每一个文本 ( ),该部分的损失最大化它与正确图像 ( ) 的相似度,同时最小化它与其他错误图像 ( ) 的相似度。这一部分确保了文本能够找到正确的图像,也就是说文本编码器能够将文本嵌入到一个空间中,使得匹配的图像与它更接近。
总损失函数
最大化图像和其正确文本描述之间的相似度,同时最小化图像和其他不匹配文本描述之间的相似度。
- ( ):文本编码器损失函数
- ( ):图像编码器损失函数
2.5 共享嵌入空间
CLIP 将图像和文本映射到相同的嵌入空间的向量,可以直接进行相似度计算。
3. CLIP 的训练方式
CLIP 的训练使用了大量的图像-文本配对数据进行对比学习。这些数据通常来自网络,例如图像和它们的自然语言描述(如社交媒体图片和它们的描述文本)。OpenAI从互联网收集了共4个亿的文本-图像对。
4. CLIP 的推理过程
在推理过程中,CLIP 通过计算图像和文本描述的相似度来执行分类或检索任务
4.1 图像分类
在图像分类任务中,CLIP 可以通过以下步骤进行推理:
- 给定一个输入图像,将其通过图像编码器生成一个向量表示。
- 使用一组标签(例如“猫”、“狗”、“汽车”等)的文本描述,将这些描述通过文本编码器生成一组向量表示。
- 计算图像向量与每个文本向量的相似度,并选择相似度最高的标签作为分类结果。
这种方式使 CLIP 能够在没有特定类别标签的情况下进行零样本分类(zero-shot classification)。
4.2 跨模态检索
在跨模态检索任务中,CLIP 可以使用文本编码器执行文本检索图像或使用图像编码器执行图像检索文本。例如:
- 输入一个文本描述,检索与之相关的图像。
- 输入一个图像,检索与之语义相关的文本描述。
5. CLIP 的优势
5.1 零样本学习
CLIP 最具创新的特性之一是它在很多任务中可以执行零样本学习。可以通过它的预训练模型处理从未见过的新任务。例如,CLIP 可以在未见过的分类标签下进行分类。
5.2 跨模态能力
CLIP 的跨模态能力使得它在图像和文本的任务中都表现出色。进行跨模态检索。
5.3 灵活性和通用性
CLIP 能够在广泛的应用场景中工作,涵盖图像分类、检索、零样本推理等任务,而不需要为每个任务单独设计和训练模型。
6. CLIP 的应用场景
6.1 零样本学习
CLIP 不依赖于特定类别标签,而是通过自然语言描述进行分类。因此,它可以在开放领域的任务中对图像进行分类,不需要专门的任务训练。
6.2 跨模态检索
CLIP 的跨模态能力使它能够通过文本查询图像,或者通过图像查询相关的文本。这种灵活性使 CLIP 在图像搜索和检索任务中表现突出。
6.3 多模态理解任务
CLIP 可以应用于图像-文本匹配、视觉问答等任务,模型能够理解图像和文本的联合语义,进而执行多模态的复杂任务。
7. CLIP 的局限性
- 依赖大规模数据,计算资源需求高:CLIP 的预训练需要大量的图像-文本配对数据和计算资源,这对于小型项目或研究可能是一个挑战。